正则表达式是一门独立的语言。如果你在学习一门新的编程语言,那它们可能是那种第一眼看上不太好懂的小语言。你必须因此去阅读额外的文章甚至书籍,以求理解它所谓的”简单“的实例。今天,我们一起回顾一下你在做下个项目前,应该知道的8个正则表达式。
正则表达式的背景
维基百科:
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
这段解释并没有真正告诉我们太多关于它实际上是以何种表现形式的。而我今天将要讲的,正是这形如,,\1,以及其它一些含义与“外表”看起来不那么一样的正则表达式。
如果你想在继续阅读之前去更多了解一下正则表达式,建议看看Regular Expressions for Dummies。
我们将要提及的8个正则表达式将能够让你学习如何去匹配: - 用户名 - 密码 - 邮箱 - 16进制(如#fff, #000) - Slug - URL - IP地址 - 还有HTML标签
随着深入,这些匹配的表达式大概将会变得更容易让人头晕。以下每一张放在开头的解释性图片,将很好的解释文章的内容,但是最后4个(正则表达式)通过阅读说明会更容易理解。
记住正则表达式含义的关键点是它们几乎都是同时向前/向后搜索的。这句话将在我们谈到HTML标签的时候会更容易理解。
注意:正则表达式中的分隔符是斜杠/。每一个匹配语句(以下也将翻译成匹配模式)开头和末尾都会跟着一个分隔符”/“。如果一个出线在表达式之内,那我们一定要通过反斜杠”"将它转义,如:“/”。
1. 匹配用户名

Matching a username
匹配模式:
/^[a-z0^9_-]{3,16}$/
解释:
让我们告诉解析器字符串的开头(通过使用^)后面跟随着的是小写字母(a-z)/数字(0-9)/下划线/下划线。接着,{3,16}确保字符串应当有至少3个这样的字符,而且不超过16个。最后,字符串抵达尾部($).
匹配
my-us3r_n4m3
不匹配
th1s1s-wayt00_l0ngt0beausername (因为太长了)
2. 匹配密码

Mathing a Password
匹配模式:
/^[a-z0-9_-]{6,18}$/
解释:
匹配密码和匹配用户名非常相似。唯一的不同是这里要6到18位字母/数字/下划线/或者连字符,而不是3到16位。
匹配
myp4ssw0rd
不匹配
mypa$w0rd(因为包含了字符)
3. 匹配16进制数

Maching a Hex Value
匹配模式:
/^#?([a-f0-9]{6}|[a-f0-9]{3})$/
解释:
符号^告诉解析器字符串从哪里开始。是否匹配#是可选的,因为它后面跟着一个问号(译者注:?代表0个获1个)。问号?告诉解释器,它前面的字符(这里是一个#)是可选的。注意问号是“贪婪的”,这意味着如果这里有匹配的字符,问号就会去获取字符。接下来,在第一组里(第一组圆括号),我们实现了两种不同的处理方式。第一个是a-f之间的小写字符或数字,要求出现6次。垂线|告诉我们,或者这里是a-f之间的小写字母或数字出现3次(译者注:这是16进制的简写)。最后,我们用$来结束字符串。
这里把“匹配6个字符的要求”放在前面的原因是,解释器先去会捕获#ffffff这样的16进制数。如果反一下,把“三个字符的要求”放在前面,那么么解释器只会拿走#fff而不会捕获其它的3个f。
匹配
#a3c113
#333
#f66h23 (匹配#f66)
不匹配
#4h82f4 (#4h8不匹配)
4. 匹配Slug

Matching a “Slug”
匹配模式:
/^[a-z0-9-]+$/
解释:
如果你曾经使用过mod_rewrite以及URL美化,那你大概是会使用正则表达式的。先让解释器去找到字符串的头(^),其后匹配一个或多个字符/数字/连字符。最后,需要匹配到的字符串到这此结束($).
匹配
my-title-here
不匹配
my_title_here (包含下划线)
5. 匹配邮件
Matching a Email
匹配模式:
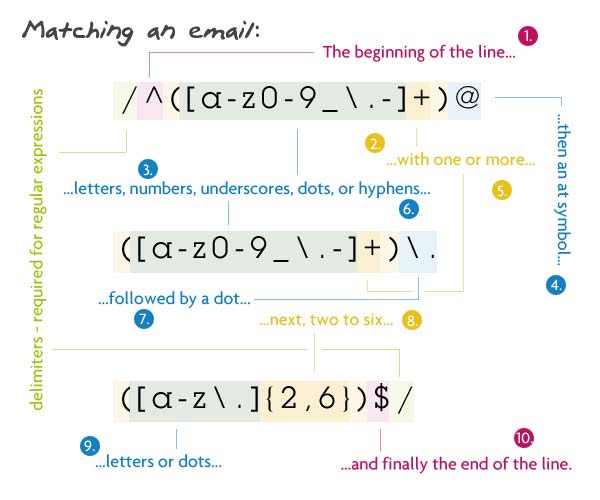
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
解释:
先让解释器找到字符串的头(^)。然后里面第一组,我们匹配一个或多个小写字母/数字/下划线/点/破折号。我转义了“.”,因为一个没有转义的“.”代表着任何字符(译者注:\. 将 “.” 转义,以匹配字符意义上的”.” )。在这个分组后面必须直接跟着一个“@”。接下来域名必须匹配上这样的规则:1个或多个小写字母,数字,下划线,点或者破折号。借着又是一个(转义的)“.”,后面跟着2到6位的小写字母或者”.”。限制2到6位是因为有国家的顶级域名这种东西(.ny.us 或者 .co.uk)。最后,我们要求字符串到此结束($)。
匹配
不匹配
[email protected] (顶级域名太长了)
6. 匹配URL

Matching a URL
匹配模式
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
(译者注:在最后一个分组内原文允许匹配空格,但URL中的空格一般在表示时通常会使用urlencode一类的来转义成“+“一类的)
解释
这个正则超像是上面所写的表达式们的杂烩形式,不过是将它们组合于一些文件结构和“ http:// ”之间罢了。其实它比看起来的样子要简单。在开始匹配之前,我们照例先搜寻用脱字符(^)来搜寻一行的开始。
第一个要捕捉的部分全部都是可选的。它允许URL以“ http:// ”开头,亦或以“ https:// ”开头,亦或都不使用上述两种。在这之后我设置了一个问号,它告诉URL去匹配https或者http.为了使整个分组可选,需要在末尾再添加一个问号。
截下来匹配域名:一个或多个数字/字母/点/连字符。域名后面跟随着一个点,之后是2-6个字母或点。接下来这部分为可选的文件/目录结构。在这个部分中,需要匹配任意数量的 斜杠/字母/下划线/点/连字符 。只要我们需要,这个部分可以匹配任意多次数。多重结构都会被匹配,但是最后以一个文件作为结尾。我在这里使用了”“而不是问号,因为”“表示0或多个,而不是表示0或1个(译者注:问号表示0或1个)。如果问号被用在这里,那么将会只有一个文件/目录能够被匹配上。
接着一个反斜杠”/“可以被匹配,但这是可选的。最后我们结束字符串。
匹配
http://net.tutsplus.com/about
不匹配
http://google.com/some/file!.html (包含感叹号)
7. 匹配IP地址

Matching an IP Address
匹配模式:
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
解释:
我不准备说谎,我没有写这个正则,而是从这里得到了它。但这不代表我现在不能逐字逐句地分析它。
第一个要求捕获的分组其实不是一个被捕获的分组(原文:The first capture group really isn’t a captured group),因为
(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.)
“?:”告诉解释器不要去捕获这个分组(更多内容在最后一个正则表达式会说明)。通过把”{3}“放在这个组别的后面,我们还要求了这个不被捕获的分组需重复3次。这个组别包含了一个子组,和一个”.”。解释器会去尝试匹配子组及”.”,然后继续。
这个子组是又一个非捕获组。它只是一堆在括号中的字符集: 1. 字符串“25”后面需要跟随0-5之间的数字; 2. 或字符“2”后面要跟着0-4,然后是一位任意数字; 3. 或是一个可选0和1,后面跟着两位数字,其中第二位是可选的。
最后我们结束匹配这个让人头晕的正则表达式。
匹配
73.60.124.136
不匹配
256.60.124.136 (第一个分组得在0-255之间)
8. 匹配HTML标签

Matching an HTML Tag
匹配模式:
/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/
解释:
又一个有用的正则表达式!它匹配任何HTML标签还有其中的内容,我们用一行的开头来开始匹配。
第一个要匹配的是标签的名字。它必须是1或多个字符。这是一个捕获组,这东西在我们捕获闭标签时相当有用。截下来是标签的属性。它是除符号>外的任意字符。因为这是可选的,但我又需要匹配上多个字符串,所以使用了符号*。加号的使用能匹配属性和值(译者注:加号代表一个或多个),星号 * 则能表示任意数量的属性。
接下里第三个是非捕获组。里面包含了一个大于号(>),一些文本内容,和一个闭标签;或是一些空格,一个反斜杠(/),\1用来表示捕获的内容要在一个捕获分组内。在这种情况下它是标签的名字。现在,如果这里不能匹配,我们就需要寻找一个自关闭标签(像是img,br,或者hr标签)。这需要有一个或多个空格,其后跟随着 “/>”。
正则表达式结束于行末。
匹配
<a href="http://net.tutsplus.com/">Nettuts+</a>
不匹配
<img src="img.jpg" alt="My image>" />
(属性中不能包含大符号)
结论
希望你能领略到正则表达式背后的一些想法和思维。愿你能在未来的项目中使用这些正则表达式!很多时候你不必一个字符一个字符地去解读正则表达式,但是有时这样做能帮助你去学习到一些东西。请记住:不要害怕正则表达式,它们不如所看到的那样(晦涩难懂),它们反而能让你的生活变得更加简单。
要不要尝试下不使用正则表达式来从字符串中抓取标签的名字呢! ;)